
열심히 코딩 하숭!
[알고리즘] 해시(Hash) | 개념정리 본문
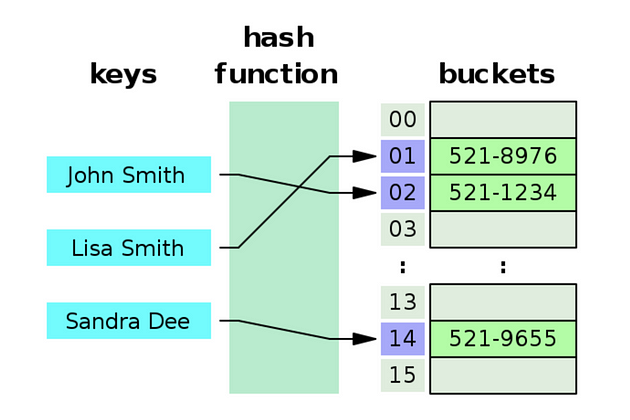
해시테이블이란?
특정 키를 빠르게 검색, 삽입, 삭제할 수 있도록 설계된 자료구조
(key값을 일일히 하나씩 비교하며 value를 찾지 않고, 해시함수를 사용해 바로 인덱스를 찾아가기 때문에 빠르다!)
충돌되었을 땐, 해시테이블에 키도 저장되어있어야 충돌 문제 해결을 할 수 있음!
그래서 보통 해시테이블에는 key와 value가 함께 저장되어있음
(이해가 되지 않는다면 아래에 나오는 충돌 문제 부분과 궁금증 부분을 확인하면 된다.)
용어
해시 함수(hash function): 입력된 키를 해시값으로 변환하여 배열의 인덱스로 변환하는 함수
해시 테이블(hash table): 해시값을 인덱스로 하여, 실제 데이터를 저장하는 배열
기본적인 동작 과정
1. 저장할 키가 주어지면, 이를 해시 함수에 넣어 해시 값을 계산
2. 계산된 해시 값에 해당하는 인덱스 위치에 데이터를 저장
3. 데이터를 검색할 때도 동일한 해시 함수로 해시 값을 계산하여 해당 인덱스로 접근해 데이터를 가져옴
시간 복잡도
Insertion & Deletion & : Search 평균적으로 O(1) / 최악의 경우 O(n)
(평균적으로 key값이 고유하기 때문에 한 번에 수행할 것을 찾을 수 있다.)
(최악일 경우, 모든 키가 동일한 해시 값을 갖게 되면 모든 데이터가 하나의 버킷에 쌓이게 된다. 우리가 원하는 값을 찾으려면 버킷의 모든 요소를 순회해야 한다.)
장점
빠른 검색 및 삽입
직접 접근: 인덱스를 통해 직접 데이터에 접근하므로, 배열과 유사하다
단점
충돌 문제: 충돌이 많이 발생할 경우 성능이 떨어질 수 있다
메모리 효율성: 해시 테이블 크기를 충분히 크게 만들어야 충돌을 줄일 수 있다
순차 접근 불가: 해시테이블은 순서가 보장되지 않는
💥 충돌 문제 💥
서로 다른 키가 해시함수로 인해 동일한 인덱스로 매칭되는 것을 "충돌(collision)"이라고 함
(예를 들어 어떤 숫자 key가 들어올 때 5로 나눈 나머지값을 해시값이라고 정의한다면, key 2와 key 7이 겹치게 된다)

발생하는 이유!
우리가 input으로 쓰는 Key값은 무한한데, 매칭되어야 하는 해시테이블의 공간은 유한하기 때문이다.
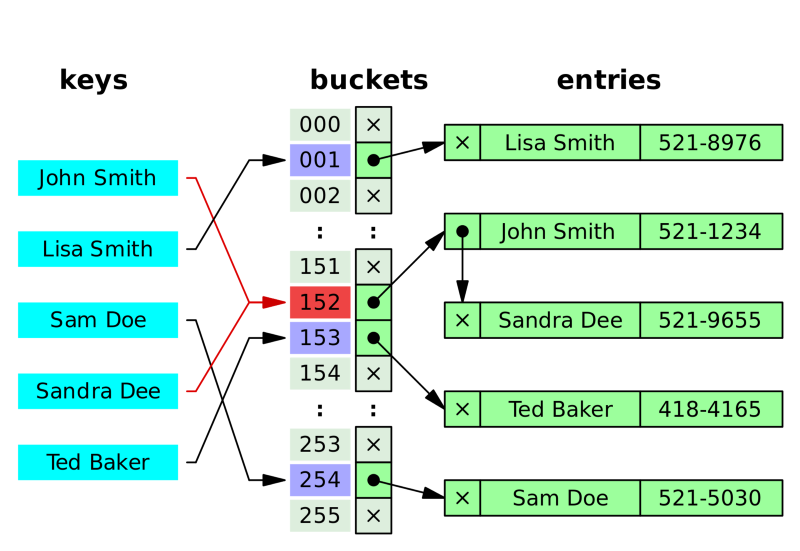
해결 방법 1. 체이닝(Chaining)
정의: 자료 저장 시 버킷에서 충돌이 일어나면 해당 값을 기존 값과 연결시킨다
아래 예제를 통해 보면, Sandra Dee가 들어갈 때 152번 버킷에서 충돌이 일어났다.
이런 상황에서 먼저 있던 John에 새로 온 Sandra를 연결리스트(Linked List)로 연결시킨다.
시간 복잡도
bucker의 길이를 n
키의 개수를 m
m/n = α 로 정의하자 (평균적으로 1개의 hash 당 (m/n) 개의 키가 들어있음!)
Insert
- 충돌이 일어났을 때 해당 해시가 가진 연결리스트의 Head에 자료를 저장할 경우 O(1)
- 충돌이 일어났을 때 해당 해시가 가진 연결리스트의 Tail에 자료를 저장할 경우 O(α)
(모든 연결리스트를 지나서 Tail에 접근해야 하기 때문)
- 최악의 경우 O(n)
(한 개의 해시에 모든 자료가 연결되어 있을 수 있기 때문)
Deletion & Search
- hash의 연결리스트를 차례로 살펴보아야 하므로 보통 O(α)
- 최악의 경우 O(n)
(한 개의 해시에 모든 자료가 연결되어 있을 수 있기 때문)
장점
한정된 bucket을 효율적으로 사용할 수 있다
해시 함수를 선택하는 중요성이 상대적으로 적어진다
상대적으로 적은 메모리를 사용한다. 미리 공간을 잡아둘 필요가 없다
단점
한 Hash에 자료들이 계속 연결된다면 쏠림현상 때문에 검색 효율을 낮출 수 있다
외부 저장공간을 사용하게 되고, 체이닝을 위한 작업을 해야한다
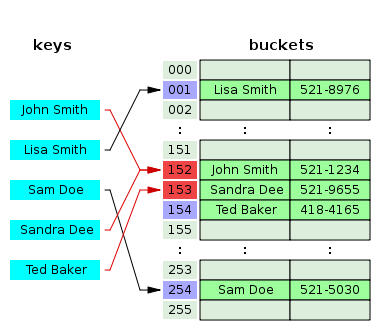
해결 방법 2. 오픈 어드레싱(Open addressing) - 개방 주소법
정의: 충돌이 일어나면 비어있는 해시를 찾아 데이터를 저장하는 기법
그러므로 해시테이블은 무조건 1개의 해시와 1개의 값이 매칭되어 있는 형태로 유지됨
아래 예시를 보면, Sandra가 저장될 때 원래 있던 152번의 John과 충돌이 일어났다.
그래서 그 다음 해시인 153번에 Sandra를 저장시키려한다.
그러고 보니 원래 153번 있던 Ted와 Sandra도 충돌됐네!
충돌 해결을 위해 원래있던 Ted를 그 다음인 154번에 배치한다.
Ted를 154번에 배치했을 때, 충돌이 일어나지 않으니 종료.
그니까 순서가 하나씩 밀린다고 보면 된다.
비어있는 해시를 찾는 규칙
(1) 선형 탐색 (Linear Probing)
- 바로 다음 해시나 n개를 건너뛰어 비어있는 해시에 데이터를 저장한다
(2) 제곱 탐색 (Quandratic Probing)
- 충돌이 일어난 해시의 제곱을 한 해시에 데이터를 저장한다
(3) 이중 해시 (Double Hashing)
- 다른 해시 함수를 한 번 더 적용한 해시에 데이터를 저장한다
시간복잡도
Insertion & Deletion & Search
- 최상의 경우 O(1)
- 최악의 경우 O(n)
(해시함수를 통해 얻은 Hash가 비어있지 않으면 그 다음 버킷을 찾아가는 과정이 계속 필요하기 때문)
그래서, Open addressing에서는 비어있는 공간을 미리 확보해두는 것이 중요하다.
(= 저장소가 어느정도 채워졌을 때, 저장소의 사이즈를 늘리는 것)
장점
또 다른 추가적인 저장공간 없이 해시테이블 내에서 데이터 저장 및 처리가 가능하다
추가적인 작업이 필요가 없다 (<-> chaining)
단점
해시 함수의 성능에, 전체 해시테이블의 성능이 좌지우지된다
데이터의 길이가 늘어나면 그에 해당하는 저장소를 마련해두어야 한다
python에서 해시 구현
체이닝 기법 적용한 해시 클래스
class HashTable:
def __init__(self, size=10):
self.size = size
self.table = [[] for _ in range(size)] # 해시 테이블을 리스트의 리스트 형태로 초기화
def hash_function(self, key):
# 간단한 해시 함수: 키를 해시하고 테이블 크기로 나눈 나머지
return hash(key) % self.size
def insert(self, key, value):
# 키를 해시하여 버킷 인덱스 찾기
index = self.hash_function(key)
# 버킷 내에서 동일한 키가 있는지 확인하여 업데이트
for pair in self.table[index]:
if pair[0] == key:
pair[1] = value
return
# 키가 존재하지 않으면 새로운 키-값 쌍 추가
self.table[index].append([key, value])
def get(self, key):
# 키를 해시하여 버킷 인덱스 찾기
index = self.hash_function(key)
# 해당 버킷에서 키를 탐색하여 값을 반환
for pair in self.table[index]:
if pair[0] == key:
return pair[1]
return None # 키가 존재하지 않을 경우 None 반환
def delete(self, key):
# 키를 해시하여 버킷 인덱스 찾기
index = self.hash_function(key)
# 버킷 내에서 키를 찾아 삭제
for i, pair in enumerate(self.table[index]):
if pair[0] == key:
del self.table[index][i]
return True
return False # 키가 존재하지 않을 경우 False 반환
def __str__(self):
# 해시 테이블 상태를 보기 쉽게 출력
return str(self.table)
# 해시 테이블 테스트
hash_table = HashTable()
hash_table.insert("apple", 10)
hash_table.insert("banana", 20)
hash_table.insert("orange", 30)
print("After insertions:", hash_table)
# 키로 값 가져오기
print("Value for 'banana':", hash_table.get("banana"))
# 키 삭제
hash_table.delete("banana")
print("After deleting 'banana':", hash_table)오픈 어드레싱 - 선형 탐사를 사용한 해시 테이블 구현
class LinearProbingHashTable:
def __init__(self, size=10):
self.size = size
self.table = [None] * size # 해시 테이블을 None으로 초기화
self.deleted = "<deleted>" # 삭제된 키를 나타내기 위한 마커
def hash_function(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self.hash_function(key)
start_index = index # 무한 루프 방지를 위한 시작 인덱스 저장
# 빈 자리 또는 삭제된 자리 또는 동일한 키를 가진 자리를 찾을 때까지 진행
while self.table[index] is not None and self.table[index] != self.deleted:
if self.table[index][0] == key:
# 키가 동일하면 값을 업데이트
self.table[index] = (key, value)
return
index = (index + 1) % self.size # 다음 인덱스로 이동
if index == start_index:
raise Exception("Hash table is full") # 해시 테이블이 꽉 찬 경우 예외 발생
# 빈 자리를 찾아 키-값 쌍 저장
self.table[index] = (key, value)
def get(self, key):
index = self.hash_function(key)
start_index = index
# 해당 인덱스부터 시작해 값을 찾을 때까지 진행
while self.table[index] is not None:
if self.table[index] != self.deleted and self.table[index][0] == key:
return self.table[index][1] # 키가 일치하면 값 반환
index = (index + 1) % self.size
if index == start_index:
break # 테이블 전체를 순회한 경우 중지
return None # 키를 찾을 수 없을 경우 None 반환
def delete(self, key):
index = self.hash_function(key)
start_index = index
# 해당 인덱스부터 시작해 키를 찾을 때까지 진행
while self.table[index] is not None:
if self.table[index] != self.deleted and self.table[index][0] == key:
self.table[index] = self.deleted # 키를 찾으면 삭제 마커로 표시
return True
index = (index + 1) % self.size
if index == start_index:
break # 테이블 전체를 순회한 경우 중지
return False # 키를 찾을 수 없을 경우 False 반환
def __str__(self):
return str(self.table)
# 해시 테이블 테스트
hash_table = LinearProbingHashTable()
hash_table.insert("apple", 10)
hash_table.insert("banana", 20)
hash_table.insert("orange", 30)
print("After insertions:", hash_table)
# 키로 값 가져오기
print("Value for 'banana':", hash_table.get("banana"))
# 키 삭제
hash_table.delete("banana")
print("After deleting 'banana':", hash_table)
궁금증
Q. python처럼 딕셔너리(Dictionary) 쓰면 되는 거 아닌가? 굳이 해시를 만든 이유는?
A1. python의 딕셔너리는 내부적으로 해시테이블을 사용함! python이면 딕셔너리를 쓰면 된다.
C, C++과 같은 언어에는 딕셔너리가 기본적으로 제공되지 않기 때문에 직접 해시 테이블을 구현해야 할 수도 있다.
A2. 기본 딕셔너리는 일반적인 키-값 쌍인데, 커스터마이징 해야하는 경우도 있을 수 있다! 그러니까 알아두는 것이 좋다.
A3. 딕셔너리는 고정된 해시테이블이 아니고, 동적으로 크기를 조정하여 충돌을 줄이는 구조다.
메모리가 제한적일 경우 직접 해시 테이블과 해시 함수를 설계해 최적화 해야할 수 있다.
A4. 해시테이블은 딕셔너리 뿐만 아니라 집합(Set)이나 캐시(Cache)와 같은 자료구조를 설계할 때도 기반이 된다.
A5. 알고리즘의 기초인 해시에 대해 알아두면, 나중에 더 복잡한 데이터 구조나 시스템 설계에도 도움이 된다!
Q. 해시테이블에 저장될 때 키값도 같이 저장되는건가?
A. 맞다! 키값은, 만약 충돌이 일어났을 때 각 값이 어떤 키에 대한 값인지 구분하기 위해 사용된다.
Q. 근데 충돌돼서 체이닝을 하지 않는 이상... 키는 저장하지 않아도 되지 않나?
A. 충돌 발생하지 않으면 해시 값만으로도 충분하다. 하지만 현실적으로 충돌을 피하는 게 어렵기 때문에! 충돌이 발생할 경우를 대비하여 저장해두는 것이 좋다.
그리고, 체이닝 뿐만 아니라 오픈 어드레싱에서도 키와 값을 함께 저장해야 한다!
예를 들어, 선형 탐사(Linear Probing)로 충돌을 해결하는 경우 해시 함수가 계산한 인덱스에 저장된 값이 없을 때까지 탐색하게 되는데, 이 과정에서 저장된 키와 검색 키가 동일한지 확인해야 하므로 키를 저장해야 한다! 아 맞네.. 오케이
참고
- chatGPT 답변
- 블로그
'코딩테스트' 카테고리의 다른 글
| [알고리즘] 스택/큐 | 개념정리 및 구현 방법 (리스트/queue/deque) (1) | 2024.11.11 |
|---|
