
열심히 코딩 하숭!
[알고리즘] 스택/큐 | 개념정리 및 구현 방법 (리스트/queue/deque) 본문
프로그래머스 알고리즘 고득점 kit 문제 풀이 스터디 2주차!
스택/큐 문제를 풀기 전에 개념정리를 하려고 한다.
스택 큐는 학교 프로그래밍(C++) 수업 때 배웠고 익숙하지만
python으로 코드를 짜려고 하니 헷갈려서 간단하게 정리를 하게 되었다!
스택
LIFO (Last In First Out) <선입후출>
가장 먼저 들어온 데이터가 가장 나중에 나간다
top을 통해서만 push 또는 pop이 가능하다.

python에서 스택 구현
python의 append() 함수를 사용해 push
pop() 함수를 사용해 pop을 진행한다.
단순하고 바로 이해된다.
모든 함수들의 계산 복잡도도 O(1)로 효율적이다
class Stack:
def __init__(self):
self.stack = []
def push(self, item):
self.stack.append(item)
print(f"Pushed {item} onto stack")
def pop(self):
if not self.is_empty():
item = self.stack.pop()
print(f"Popped {item} from stack")
return item
else:
print("Stack is empty, cannot pop")
return None
def peek(self):
if not self.is_empty():
return self.stack[-1]
else:
print("Stack is empty, nothing to peek")
return None
def is_empty(self):
return len(self.stack) == 0
def size(self):
return len(self.stack)
# 테스트 코드
if __name__ == "__main__":
stack = Stack()
stack.push(10)
stack.push(20)
print(f"Top item is: {stack.peek()}")
stack.pop()
stack.pop()
stack.pop() # 빈 스택에서 pop 시도큐
FIFO (Firsth In First Out) <선입선출>
먼저 들어온 데이터가 먼저 나간다
큐에 데이터를 넣는 것을 enqueue라고 하고
빼는 것을 dequeue라고 한다.
python에서 큐 구현
시간 복잡도를 고려하지 않는다면, 아래와 같이 구현하면 된다.
(1) 리스트 자료형 사용
queue = []
queue.append(1) # enqueue
queue.append(2)
queue.append(3)
print(queue.pop(0)) # dequeue, O(n)
enqueue는 append() 함수 사용
dequeue는 pop(0) 함수 사용 (가장 먼저 들어온 것을 내보내야 하니까!)
여기서 문제는, pop(0) 함수의 시간 복잡도가 O(n)이라는 것이다.
첫번째 요소를 제거하는 것은 시간복잡도 O(1) 밖에 소요되지 않지만,
0번째 요소를 제거하고 나서, 나머지 요소들을 모두 한 칸씩 앞으로 이동해야하기 때문에 각 요소에 대한 복사 연산이 필요하게 된다.
그래서, 다음 두가지 방법을 사용하면 시간 복잡도 측면에서 더 효율적이게 문제를 풀 수 있다.
(2) queue 사용
enqueue는 put()
dequeue는 get()이다
내부적으로 링 버퍼(ring buffer)와 같은 자료구조를 사용해 큐의 데이터를 관리한다.
링 버퍼란?
고정된 크기의 배열을 사용하며,
배열의 끝과 시작이 연결된 원형 형태로 동작한다! (학교 자료구조 시간에 배웠던 게 생각난다)
- 고정 크기
- 헤드 포인터: 데이터가 제거되는 위치를 가리킴
- 테일 포인터: 데이터가 추가되는 위치를 가리킴
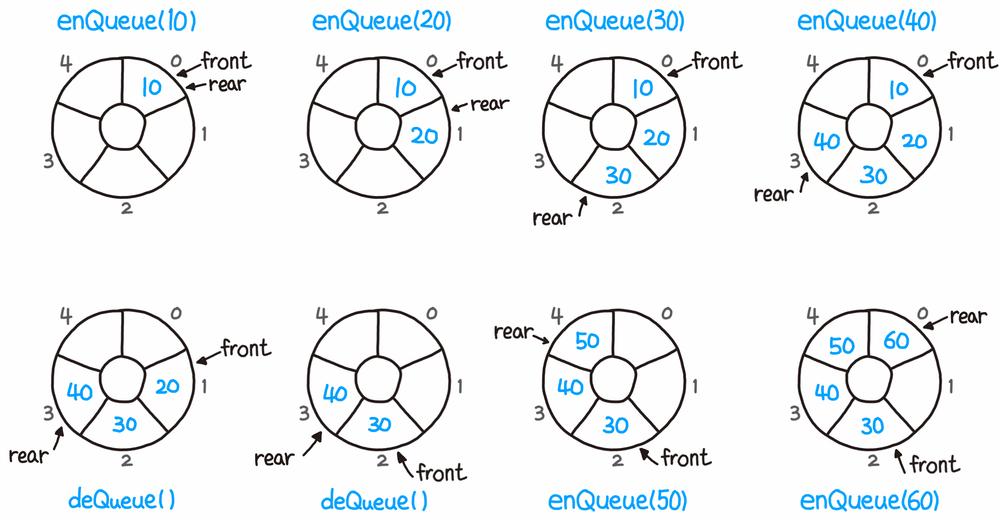
동작 방식
Enqueue(삽입)
- 데이터를 테일 포인터 위치에 삽입하고, 테일 포인터는 다음 위치로 이동한다
- 테일 포인터가 배열의 끝을 넘어가면 처음 위치로 돌아온다 (원형 구조이기 때문!)
Dequeue(제거)
- 데이터를 헤드 포인터 위치에서 제거하고, 헤드 포인터는 다음 위치로 이동한다
- 헤드포인터가 배열의 끝을 넘어가면 처음 위치로 돌아온다.
포인터 겹침 방지
- 버퍼가 가득 찬 경우, 테일 포인터가 헤드 포인터를 넘지 않도록 관리한다.
링 버퍼를 직접 코드로 구현한 것을 보면 잘 이해가 될 것이다.
접은글로 첨부했으니 확인!
class RingBufferQueue:
def __init__(self, size):
self.size = size # 큐의 크기
self.buffer = [None] * size # 고정 크기의 배열
self.head = 0 # 큐의 앞 부분 (첫 번째 요소)
self.tail = 0 # 큐의 뒤 부분 (마지막 요소)
self.count = 0 # 큐에 들어있는 아이템 수
def is_empty(self):
return self.count == 0
def is_full(self):
return self.count == self.size
def enqueue(self, item):
if self.is_full():
raise Exception("Queue is full")
self.buffer[self.tail] = item
self.tail = (self.tail + 1) % self.size # 원형 큐에서 다음 위치로 이동
self.count += 1
def dequeue(self):
if self.is_empty():
raise Exception("Queue is empty")
item = self.buffer[self.head]
self.head = (self.head + 1) % self.size # 원형 큐에서 다음 위치로 이동
self.count -= 1
return item
def peek(self):
if self.is_empty():
raise Exception("Queue is empty")
return self.buffer[self.head]
def __str__(self):
if self.is_empty():
return "Queue is empty"
return f"Queue contents: {self.buffer[self.head:self.tail]}"
# 사용 예시
queue = RingBufferQueue(5)
# 데이터 삽입
queue.enqueue(10)
queue.enqueue(20)
queue.enqueue(30)
queue.enqueue(40)
queue.enqueue(50)
print(queue) # 큐 내용 출력
# 큐에서 데이터 제거
print("Dequeue:", queue.dequeue())
print(queue)
# 큐에 데이터 삽입 후
queue.enqueue(60)
print(queue)
# 큐에서 데이터를 확인
print("Peek:", queue.peek())
멀티스레드 환경에서 스레드-안전성을 제공하는 큐를 구현할 때 유용하다고 한다.
멀티스레드란?
하나의 프로그램 내에서 여러개의 스레드(작업단위)가 동시에 실행되는 프로그래밍 방식
(링 버퍼는 구조적으로 데이터의 삽입과 제거가 고정된 메모리 공간에서 이루어지며, 포인터만 이동시키기 때문에 동기화 메커니즘과 결합하면 안전하게 동작할 수 있다)
동기화 메커니즘이란?
스레드 간의 데이터 접근을 제어하기 위해 락(Lock)을 거는 등과 같이 동기화 도구를 사용하는 것
만약 멀티스레드 프로그래밍이 필요하지 않은 경우, 더 간단하고 빠른 deque를 사용하는 게 낫다고 한다!
코드
from queue import Queue
q = Queue()
q.put(1) # enqueue
q.put(2)
q.put(3)
print(q.get()) # dequeue, O(1)
(3) deque 사용
deque는 double-ended queue의 약자로, 데이터의 양쪽 끝에서 삽입과 삭제가 모두 가능하다!
시간 복잡도가 모두 O(1)로 매우 효율적이다.
( (2)에 나와있는 Queue보다 더 간단하고 빠르다고 한다. )
collections.deque 클래스를 이용하면 된다.
- append() <- 기본값은 right
- pop() <- 기본값은 right
- appendleft()
- pop(left)
from collections import deque
dq = deque()
dq.append(1) # enqueue
dq.append(2)
dq.append(3)
print(dq.popleft()) # dequeue, O(1)
출처
chatGPT 답변
'코딩테스트' 카테고리의 다른 글
| [알고리즘] 해시(Hash) | 개념정리 (1) | 2024.11.03 |
|---|
