
열심히 코딩 하숭!
8. MNIST를 활용한 숫자 인식 | 파이토치 딥러닝 프로그래밍 본문
08 MNIST를 활용한 숫자 인식
8.1 문제 정의
- MNIST 데이터
- 손글씨 데이터
- 가로 세로 28 x 28 (pixel)
- 색의 농도는 0 ~ 225까지
- 데이터 사용
- 이미지 한 장은 [1, 28, 28] 형태로 구성되어있음 (맨 처음 1은 이미지의 색을 의미하는 채널의 차원수 - 그니까 2차원의 데이터인데 색이 붙어서 3차원…!!!이 된!!!)
- 이번 장에서는 1계 텐서 형식으로 입력 데이터를 변환하여 사용
- 이미지 한 장 → 784개(28 X 28)의 요소를 1차원 배열로 전개
- class
- 0 ~ 9까지의 숫자를 분류 → 총 10개의 class
8.2-8.3 중요 개념 / 신경망과 딥러닝
pass
8.4 활성화 함수와 ReLU 함수
- ReLU 함수
- x<0 → 0
- x≥0 → y=x
- 간단하지만, x=0에서 서로 다른 함수로 바뀌기 때문에 비선형 함수임!

8.5 GPU 사용하기
- GPU 디바이스 확인
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
## 결과 ##
cuda:0 <- GPU 사용 가능
2. GPU 사용 규칙
- 텐서 변수는 데이터가 CPU / GPU 중 어디에 속해 있는지를 속성으로 가짐
- CPU와 GPU 사이에서 데이터는 to함수로 전송
- 두 변수가 올라가있는 위치가 다를 경우 연산 에러가 남
# to 함수를 사용하여, 생성한 모델을 GPU로 전송
net = Net(n_input, n_output, n_hidden).**to(device)**
💡 궁금한 점: GPU에서 CPU로 보내는 방법은? 아래의 코드처럼!
# GPU 텐서 생성
tensor = torch.tensor([1, 2, 3]).cuda()
# GPU에서 CPU로 텐서 이동
tensor_cpu = [tensor.to](<http://tensor.to/>)('cpu')
8.6-8.14 MNIST 데이터 학습하기
1. 데이터 가져오기
import torchvision.datasets as datasets
data_root = './data' # 다운로드 받을 디렉터리명
train_set0 = datasets.MNIST(
root = data_root, # 디렉터리 지정
train = True, # 훈련 데이터인지 검증 데이터인지
download = True) # 원본 데이터가 없는 경우, 다운로드를 실행하는지 여부
!ls -lR ./data/MNIST # 다운로드한 파일 확인
- (입력 데이터, 정답 데이터) 형태로 파이썬 리스트에 저장되어있다
print(len(train_set0)) # 데이터 개수 확인
image, label = train_set0[0] # 첫번째 요소 가져오기
print(type(image))
print(type(label))
## 결과 ##
60000
<class 'PIL.Image.Image'>
<class 'int'>
- 입력 데이터를 이미지로 출력
plt.figure(figsize=(1,1))
plt.title(f'{label}')
plt.imshow(image, cmap='gray_r')
plt.axis('off')
plt.show()
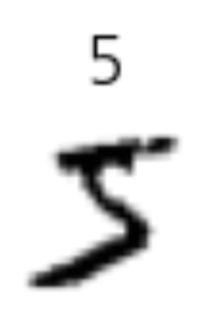
2. 데이터 전처리
- ToTensor - 입력 데이터의 형식을 텐서로 변경
transforms.ToTensor(), # 데이터를 텐서로 변환
- Normalize - 데이터 정규화
- 범위 [0, 1] → 범위 [-1, 1]로 변환
- 표준편차의 값을 0.5로 설정
transforms.Normalize(0.5, 0.5), # 데이터 정규- Lambda 클래스를 사용하여 1차원 텐서로 변환
transforms.Lambda(lambda x: x.view(-1)), # 현재 텐서를 1계 텐서로 변환- 전처리
transform = transforms.Compose([
transforms.ToTensor(), # (1) 데이터를 텐서로 변환
transforms.Normalize(0.5, 0.5), # (2) 데이터 정규화 [-1, 1]로 조정
transforms.Lambda(lambda x: x.view(-1)), # (3) 1계 텐서로 변환
])
# 훈련용 데이터셋
train_set = datasets.MNIST(
root = data_root, train = True,
download = True, transform = transform)
# 검증용 데이터셋
test_set = datasets.MNIST(
root = data_root, train = False, # 검증일 경우 train = False
download = True, transform = transform)3. 미니 배치 데이터 생성
from torch.utils.data import DataLoader
# 미니 배치 사이즈
batch_size = 500
# 훈련용 데이터로더
# 훈련용이므로, 셔플을 적용함
train_loader = DataLoader(
train_set, batch_size = batch_size,
shuffle = **True**)
# 검증용 데이터로더
# 검증시에는 셔플을 필요로하지 않음
test_loader = DataLoader(
test_set, batch_size = batch_size,
shuffle = False)
# 몇 개의 그룹으로 데이터를 가져올 수 있는가
print(len(train_loader))
# 데이터로더로부터 가장 처음 한 세트를 가져옴
for images, labels in train_loader:
break
print(images.shape)
print(labels.shape)
## 결과 ##
120
torch.Size([500, 784])
torch.Size([500])4. 모델 정의
- 입력 출력 차원수 정의
# 입력 차원수
n_input = image.shape[0] # 784
# 출력 차원수
# 분류 클래스 수는 10
n_output = len(set(list(labels.data.numpy())))
# 은닉층의 노드 수
n_hidden = 128
- 모델 클래스 정의(784입력 10출력 1은닉층의 신경망 모델)
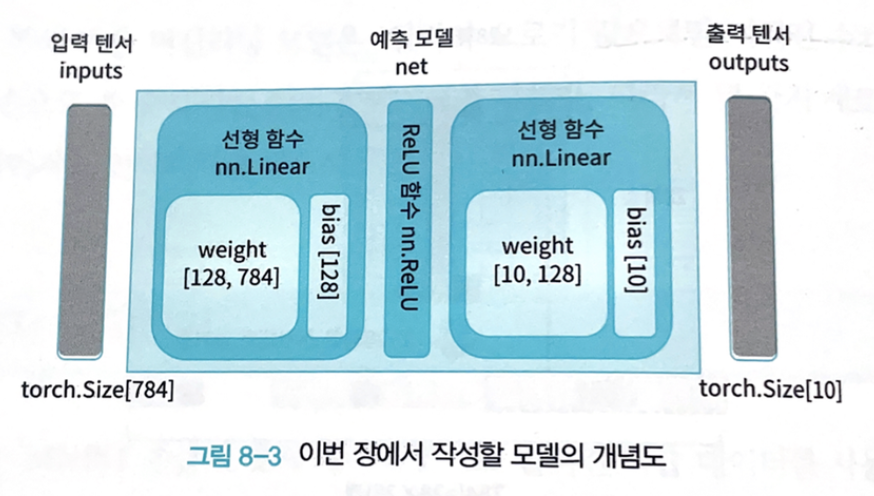
class Net(nn.Module):
def __init__(self, n_input, n_output, n_hidden):
super().__init__()
# 은닉층 정의(은닉층 노드 수 : n_hidden)
self.l1 = nn.Linear(n_input, n_hidden)
# 출력층 정의
self.l2 = nn.Linear(n_hidden, n_output)
# ReLU 함수 정의
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x1 = self.l1(x)
x2 = self.relu(x1)
x3 = self.l2(x2)
return x3- 모델 변수 생성
# 난수 고정
torch.manual_seed(123)
torch.cuda.manual_seed(123)
# 모델 인스턴스 생성
net = Net(n_input, n_output, n_hidden)
# 모델을 GPU로 전송
net = net.to(device)
print(net)
## 결과 ##
Net(
(l1): Linear(in_features=784, out_features=128, bias=True)
(l2): Linear(in_features=128, out_features=10, bias=True)
(relu): ReLU(inplace=True)
)5. 경사 하강법
- 예측 계산
for images, labels in train_loader: # 훈련데이터의 가장 처음 항목을 취득
break
# 데이터로더에서 취득한 데이터를 GPU로 보냄
inputs = images.to(device)
labels = labels.to(device)
# 예측 계산
outputs = net(inputs)
# 결과 확인
print(outputs)- 손실 계산
# 손실 계산
loss = criterion(outputs, labels)
# 손실값 가져오기
print(loss.item())
# 손실 계산 그래프 시각화
g = make_dot(loss, params=dict(net.named_parameters()))
display(g)
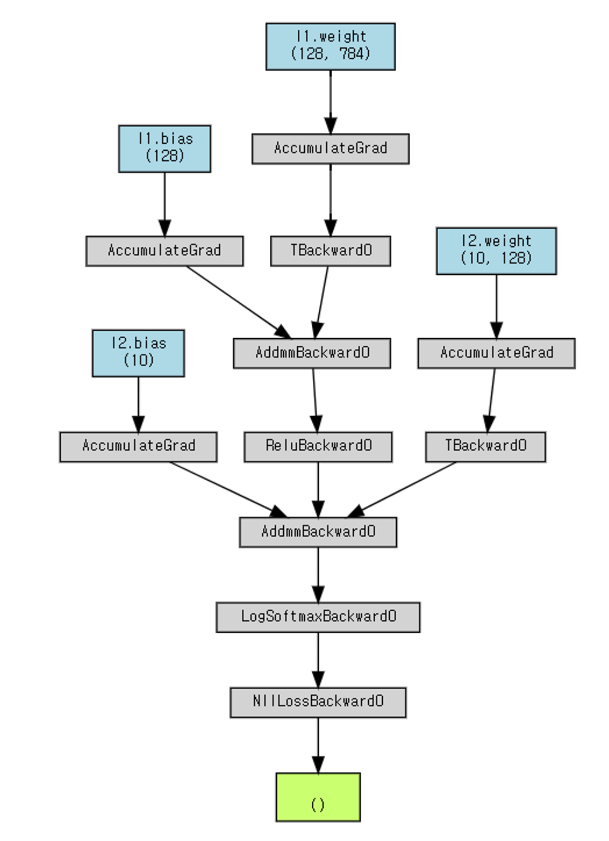
💡 그래프 이해가 안 된다!!!! 화살표가 반대인건가?
- 화살표 방향 → 순전파에 대한 방향을 나타낸 것임!
- 반복 처리
# 난수 고정
torch.manual_seed(123)
torch.cuda.manual_seed(123)
torch.backends.cudnn.deterministic = True
torch.use_deterministic_algorithms = True
# 학습률
lr = 0.01
# 모델 초기화
net = Net(n_input, n_output, n_hidden).to(device)
# 손실 함수: 교차 엔트로피 함수
criterion = nn.CrossEntropyLoss()
# 최적화 함수: 경사 하강법
optimizer = optim.SGD(net.parameters(), lr=lr)
# 반복 횟수
num_epochs = 100
# 평가 결과 기록
history = np.zeros((0,5))
# tqdm 라이브러리 임포트
from tqdm.notebook import tqdm
# 반복 계산 메인 루프
for epoch in range(num_epochs):
train_acc, train_loss = 0, 0
val_acc, val_loss = 0, 0
n_train, n_test = 0, 0
# 훈련 페이즈
for inputs, labels in tqdm(train_loader):
n_train += len(labels)
# GPU로 전송
inputs = inputs.to(device)
labels = labels.to(device)
# 경사 초기화
optimizer.zero_grad()
# 예측 계산
outputs = net(inputs)
# 손실 계산
loss = criterion(outputs, labels)
# 경사 계산
loss.backward()
# 파라미터 수정
optimizer.step()
# 예측 라벨 산출
predicted = torch.max(outputs, 1)[1]
# 손실과 정확도 계산
train_loss += loss.item()
train_acc += (predicted == labels).sum().item()
# 예측 페이즈
for inputs_test, labels_test in test_loader:
n_test += len(labels_test)
inputs_test = inputs_test.to(device)
labels_test = labels_test.to(device)
# 예측 계산
outputs_test = net(inputs_test)
# 손실 계산
loss_test = criterion(outputs_test, labels_test)
# 예측 라벨 산출
predicted_test = torch.max(outputs_test, 1)[1]
# 손실과 정확도 계산
val_loss += loss_test.item()
val_acc += (predicted_test == labels_test).sum().item()
# 평가 결과 산출, 기록
train_acc = train_acc / n_train
val_acc = val_acc / n_test
train_loss = train_loss * batch_size / n_train
val_loss = val_loss * batch_size / n_test
print (f'Epoch [{epoch+1}/{num_epochs}], loss: {train_loss:.5f} acc: {train_acc:.5f} val_loss: {val_loss:.5f}, val_acc: {val_acc:.5f}')
item = np.array([epoch+1 , train_loss, train_acc, val_loss, val_acc])
history = np.vstack((history, item))6. 결과 확인
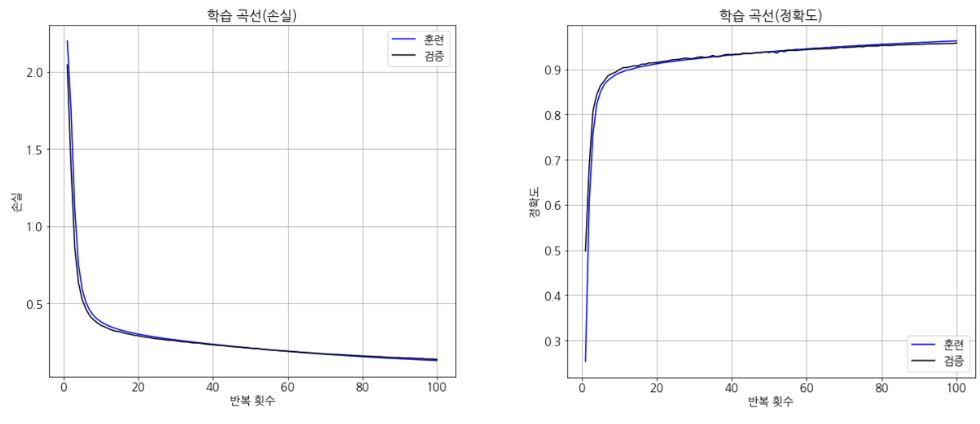
- 최종 손실 및 정확도
# 손실과 정확도 확인
print(f'초기상태 : 손실 : {history2[0,3]:.5f} 정확도 : {history2[0,4]:.5f}' )
print(f'최종상태 : 손실 : {history2[-1,3]:.5f} 정확도 : {history2[-1,4]:.5f}')
## 결과 ##
초기상태 : 손실 : 2.04576 정확도 : 0.49800
최종상태 : 손실 : 0.13873 정확도 : 0.95810
- 손실 / 정확도 곡선
'프로그래밍 책 > 파이토치 딥러닝 프로그래밍' 카테고리의 다른 글
| 10. 튜닝 기법 | 파이토치 딥러닝 프로그래밍 (1) | 2024.04.21 |
|---|---|
| 9. CNN을 활용한 이미지 인식 | 파이토치 딥러닝 프로그래밍 (1) | 2024.04.21 |
| 4. 예측 함수 정의하기 | 파이토치 딥러닝 프로그래밍 (1) | 2024.04.17 |
| 3. 처음 시작하는 머신러닝 | 파이토치 딥러닝 프로그래밍 (0) | 2024.04.17 |
| 2. 파이토치의 기본 기능 | 파이토치 딥러닝 프로그래밍 (0) | 2024.04.16 |
'프로그래밍 책/파이토치 딥러닝 프로그래밍' Related Articles
more



