
열심히 코딩 하숭!
9. CNN을 활용한 이미지 인식 | 파이토치 딥러닝 프로그래밍 본문
09 CNN을 활용한 이미지 인식
9.1 문제 정의
CIFAR-10
- 32 x 32 화소의 컬러 이미지 데이터
- 이미지를 학습하여 해당하는 이미지의 카테고리를 예측
- 컬러이므로 → (3, 32, 32)

🌟채널🌟
- 이미지 → ‘색, 가로, 세로’의 3계 텐서의 구조를 유지 (여기에서 ‘색’이 채널!)
- RGB라면 채널은 3
- 흑백 등 단일 색상일 경우 채널은 1
- 두번째 층 이후에서는 ‘색’에 해당하는 인덱스는 더 이상 색의 의미를 갖지 않게 된다
- ⇒ 학습하면서 다른 특징에 초점을 맞출 수 있기 때문
- 이렇게 깊이에 해당하는 인덱스는 ‘채널’이라고 불림
| 📌 채널이 4개 이상일 경우? → 다중 모달 데이터 (자연어처리) → 시간 차원 (비디오) → 3D 이미지 → 특징 추출: 일부 심층 학습 아키텍처에서는 채널 수를 증가시켜 모델의 표현력을 향상시키기 위해 사용될 수 있음. (이는 특정 계층에서 다양한 특징을 추출하고 다양한 측면에서 입력 데이터를 보다 효과적으로 모델링하기 위해 사용될 수 있다.) 채널을 색으로 예를들어 소개하는 블로그가 많아서 헷갈렸음! 색도 하나의 “특징”으로 생각하면 이해됨 |
9.3 CNN의 처리 개요
합성곱(Convolution)
- 커널: 정방형의 배열
- 처리 방법: 원본 이미지를 커널과 같은 크기의 정방형 영역으로 잘라내고 대응하는 각 요소에 곱연산을 취함
- 도형의 특징량을 추출하는데 탁월함
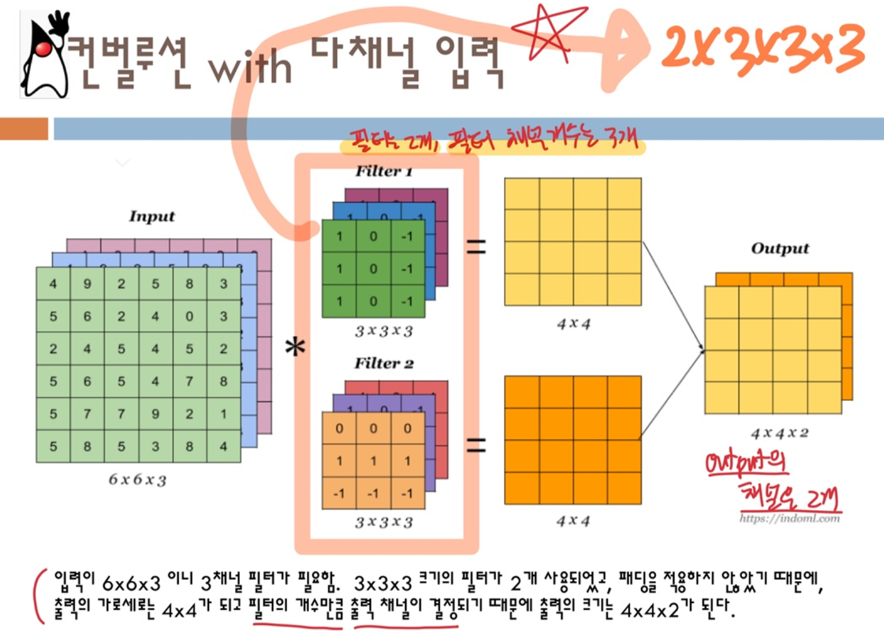
- 커널은 입력 채널의 분량만큼 있어야 한다
- 학습 대상: 커널 배열이 신경망에서의 ‘파라미터’에 해당
- 커널의 특징
📌 커널이 위치를 이동하며 학습이 이뤄지므로 위치의 이동과 관련이 없는 특징량을 검출할 수 있게 된다
|
풀링(Pooling)
- 입력 데이터의 다운샘플링을 통해 공간 크기를 줄이고 중요한 특징을 강조하는 과정
- maxpooling: 2x2와 같이 작은 사각형으로 이미지를 잘라내어 그 범위 안에서 최대값을 구함
- 풀링은 보통 컨볼루션과 달리 중첩되는 영역이 없게끔 옮겨가며 처리하는 게 일반적이다
- 이미지 축소와 동일한 효과를 얻을 수 있음
| 📌 컨볼루션 / 풀링에서 감소되는 이미지 크기 계산 방법
|
📍 Padding
 |
9.4 파이토치에서 CNN을 구현하는 방법
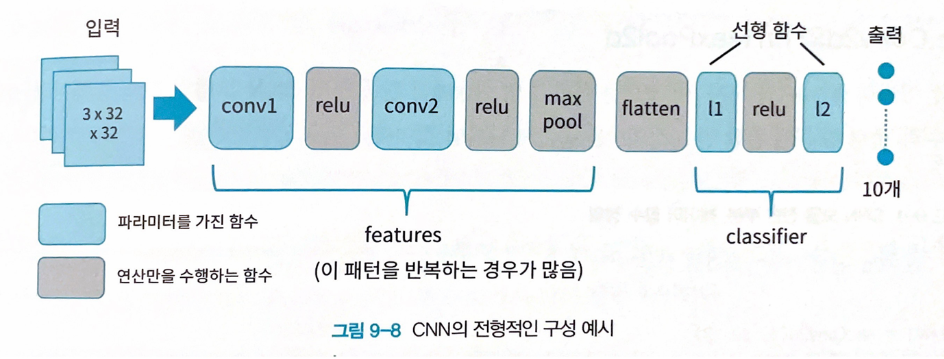
nn.Conv2d
- 합성곱 함수
- 파라미터 가짐
nn.MaxPool2d
- maxpool 풀링 함수
- 파라미터 X
nn.Conv2d와 nn.MaxPool2d 코드
conv1 = nn.Conv2d(3, 32, 3) # 입력 채널 수 / 출력 채널 수 / 커널 사이즈(nxn)
relu = nn.ReLU(inplace=True)
conv2 = nn.Conv2d(32, 32, 3)
maxpool = nn.MaxPool2d((2,2)) # 사각형 가로, 세로
print(conv1)
print(conv1.weight.shape)
print(conv1.bias.shape)
print(conv2.weight.shape)
print(conv2.bias.shape)
## 결과 ##
Conv2d(3, 32, kernel_size=(3,3), stride=(1,1))
torch.Size([32, 3, 3, 3]) # weight는 4계 텐서임
torch.Size([32])
torch.Size([32, 32, 3, 3]) # weight는 4계 텐서임
torch.Size([32])- 여기는 컨볼루션 속의 weight와 bias를 shape으로 나타낸 것임
| 📍 컨볼루션에서 가중치 함수의 shape에 대해 [32, 3, 3, 3] 1) 32개의 출력 채널수를 가져야 한다! 2) 입력 이미지가 RGB 채널을 가지니까 입력 채널 수인 3!! 3, 4) 3x3 짜리의 커널이! ⇒ 학교 강의자료
 |
컨볼루션, 풀링 시뮬레이션 코드
# 임의로 텐서 생성
inputs = torch.randn(100, 3, 32, 32)
print(inputs.shape)
# CNN 전반부 처리
x1 = conv1(inputs)
x2 = relu(x1)
x3 = conv2(x2)
x4 = relu(x3)
x5 = maxpool(x4)
print(inputs.shape, x1.shape, x2.shape, x3.shape, x4.shape, x5.shape)
## 결과 ##
# [데이터 건수, 채널 수, 가로 화소 수, 세로 화소 수]
torch.Size([100, 3, 32, 32])
torch.Size([100, 32, 30, 30]) -> x1
torch.Size([100, 32, 30, 30]) -> x2
torch.Size([100, 32, 28, 28]) -> x3
torch.Size([100, 32, 28, 28]) -> x4
torch.Size([100, 32, 14, 14]) -> x5
- 여기는 데이터가 함수에 들어갔다가 나왔을 때의 shape를 나타낸 것
- 첫번째 숫자[학습셋 데이터 건수]: 일정하게 100
- 두번째 숫자[채널 수]: 처음에는 RGB 채널이 3장이므로 3이 입력되었고 이후 출력 채널수를 = 32로 설정함에 따라, 두번째값이 32로 나타났다
- 세번째, 네번째 숫자[가로, 세로 화소 수]: 처음에는 이미지 사이즈인 32x32이고, 이후 컨볼루션 그리고 풀링으로 인해 화소 수가 감소하는 것을 확인할 수 있다
nn.Sequential
- 여러 함수의 합성 함수로 구성되어 직렬로 이어져 있음
- 파이토치에서 ‘컨테이너’라고 불림
features = nn.Sequential(
conv1,
relu,
conv2,
relu,
maxpool
)
outputs = features(inputs)
nn.Flatten
- 1계화 함수
- 선형 함수(nn.Linear)에서 사용할 수 있게끔, 가로 1열의 1계 텐서로 만들어줌 (마지막 출력에 대한 조작이 필요할 때 사용)
flatten = nn.Flatten()
outputs2 = flatten(outputs)
print(outputs.shape)
print(outputs2.shape)
## 결과 ##
torch.Size([100, 32, 14, 14])
torch.Size([100, 6272]) # 32 x 14 x 14
9.5 공통 함수 사용하기
eval_loss (손실 계산)
- 손실을 계산하면, 변수를 사용하여 손실 계산 그래프를 시각화할 수 있다
- 흐름
- loader: 데이터 로더로 입력 데이터와 정답 데이터를 가져온다
- 입력 데이터와 모델 인스턴스로부터 예측 값을 계산
- 예측 값과 정답 데이터를 사용하여 손실 계산
def eval_loss(loader, device, net, criterion):
for images, labels in loader: # 처음 한 개 세트를 가져옴
break
# 디바이스 할당
inputs = images.to(device)
labels = labels.to(device)
# 예측 계산
outputs = net(inputs)
# 손실 계산
loss = criterion(outputs, labels)
return loss
fit (학습)
- 반복 계산 부분을 한 번에 처리
- 인수
- net: 학습 대상의 모델 인스턴스
- optimizer: 최적화 함수의 인스턴스
- criterion: 손실 함수의 인스턴스
- num_epochs: 반복 횟수
- train_loader: 훈련용 데이터로더
- test_loader: 검증용 데이터로더
- device: GPU 또는 CPU
- history: 계산 도중의 history (지금까지의 결과를 넘겨받아 추가 학습을 진행할 수 있음)
- 반환
- history: (반복 횟수, 훈련 손실, 훈련 정확도, 검증 손실, 검증 정확도)의 2차원 넘파이 배열
def fit(net, optimizer, criterion, num_epochs, train_loader, test_loader, device, history):
from tqdm.notebook import tqdm
base_epochs = len(history)
for epoch in range(base_epochs, num_epochs+base_epochs):
train_loss = 0
train_acc = 0
net.train()
count = 0
for inputs, labels in tqdm(train_loader):
count += len(labels)
inputs = inputs.to(device)
labels = labels.to(device)
net.eval()
count = 0
for inputs, labels in test_loader:
count += len(labels)
inputs = inputs.to(device)
labels = labels.to(device)
evaluate_history (학습 로그)
- history를 인수로 받아와서 아래와 같은 역할을 수행한다
- history 앞부분과 마지막 부분을 print 함수로 표시해서 학습 결과의 개요를 표시한다
- 학습 곡선을 손실, 정확도 두 가지로 출력
show_images_labels (예측 결과 표시)
- 모델이 올바르게 예측하고 있는지, 데이터 이미지 출력 등을 수행
- 주로 데이터 시각화 및 디버깅 목적으로 사용
- 인수
- loader: 검증용 데이터로더
- classes: 정답 데이터에 대응하는 라벨 값의 리스트 ([plane, car, bird]와 같은)
- net: 사전에 학습이 끝난 모델 인스턴스 (None을 넘기면 정답 데이터만 표시됨)
- device: 예측 계산에 사용하는 디바이스
if net is not None:
predicted_name = classed[predicted[i]]
# 정답인지 아닌지 색으로 구분
if label_name == predicted_name:
c = 'k'
else:
c = 'b'
ax.set_title(label_name + ':' + predicted_name, c=c, fontsize=20)
else:
ax.set_title(label_name, fontsize=20)
torch_seed (난수 고정)
- 항상 동일한 결과를 얻기 위한 처리
def torch_seed(seed=123):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True # GPU 사용 시 동일한 결과 얻을 수 있도록 추가 호출
torch.use_deterministic_algorithms = True # GPU 사용 시 동일한 결과 얻을 수 있도록 추가 호출9.6 데이터 준비
Transforms 정의
# transform1 - 정규화 및 1계 텐서화
transform1 = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5),
transforms.Lambda(lambda x: x.view(-1)),
])
# transform2 - 정규화만 시킴
transform2 = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5),
])
데이터셋 정의
data_root = './data'
# 훈련 데이터셋 (1계 텐서 버전)
train_set1 = datasets.CIFAR10(
root = data_root, train = True,
download = True, transform = transform1)
# 검증 데이터셋 (1계 텐서 버전)
test_set1 = datasets.CIFAR10(
root = data_root, train = False, # 검증이므로 False
download = True, transform = transform1)
# 훈련 데이터셋 (3계 텐서 버전)
train_set2 = datasets.CIFAR10(
root = data_root, train = True,
download = True, transform = transform2)
# 검증 데이터셋 (3계 텐서 버전)
test_set2 = datasets.CIFAR10(
root = data_root, train = False, # 검증이므로 False
download = True, transform = transform2)

데이터로더 정의
# 미니 배치 사이즈 지정
batch_size = 100
# 훈련용 데이터로더
# 훈련용이므로 셔플을 True로 설정
train_loader1 = DataLoader(train_set1, batch_size=batch_size, shuffle=True)
# 검증용 데이터로더
# 검증용이므로 셔플하지 않음
test_loader1 = DataLoader(test_set1, batch_size=batch_size, shuffle=False)
# 훈련용 데이터로더
# 훈련용이므로 셔플을 True로 설정
train_loader2 = DataLoader(train_set2, batch_size=batch_size, shuffle=True)
# 검증용 데이터로더
# 검증용이므로 셔플하지 않음
test_loader2 = DataLoader(test_set2, batch_size=batch_size, shuffle=False)
검증 데이터를 이미지로 표시
- test_loader2에서 가져와서 처음 50개의 이미지를 표시
- 모델을 사용하지 않고 정답을 타이틀로 함께 표시
# 정답 라벨 정의
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 검증 데이터의 처음 50개를 출력
show_images_labels(test_loader2, classes, None, None)

9.7 모델 정의 (전결합형)
각 노드의 차원수 설정
# 입력 차원수는 3*32*32=3072
n_input = image1.view(-1).shape[0]
# 출력 차원수
# 분류 클래스의 수이므로 10
n_output = len(set(list(labels1.data.numpy())))
# 은닉층의 노드수
n_hidden = 128
# 결과 확인
print(f'n_input: {n_input} n_hidden: {n_hidden} n_output: {n_output}')

모델 정의
# 3072입력 10출력 1은닉층을 포함한 신경망 모델
class Net(nn.Module):
def __init__(self, n_input, n_output, n_hidden):
super().__init__()
self.l1 = nn.Linear(n_input, n_hidden) # 은닉층 정의(은닉층의 노드수 : n_hidden)
self.l2 = nn.Linear(n_hidden, n_output) # 출력층의 정의
self.relu = nn.ReLU(inplace=True) # ReLU 함수 정의
def forward(self, x):
x1 = self.l1(x)
x2 = self.relu(x1)
x3 = self.l2(x2)
return x3
9.8 결과 (전결합형)
학습
- fit 함수를 도입하여 학습 코드 구현을 한 줄로 간단하게 마무리 지을 수 있다
torch_seed() # 난수 설정
net = Net(n_input, n_output, n_hidden).to(device) # 모델 인스턴스 생성
criterion = nn.CrossEntropyLoss() # 손실 함수: 교차 엔트로피 함수
# => 해당 손실함수를 통해 분류 확률 계산
# 학습률
lr = 0.01
optimizer = optim.SGD(net.parameters(), lr=lr) # 최적화 함수: 경사 하강법
# 반복 횟수
num_epochs = 50
# 평가 결과 기록
history = np.zeros((0,5))
# 학습
history = fit(net, optimizer, criterion, num_epochs, train_loader1, test_loader1, device, history)
평가
evaluate_history(history)
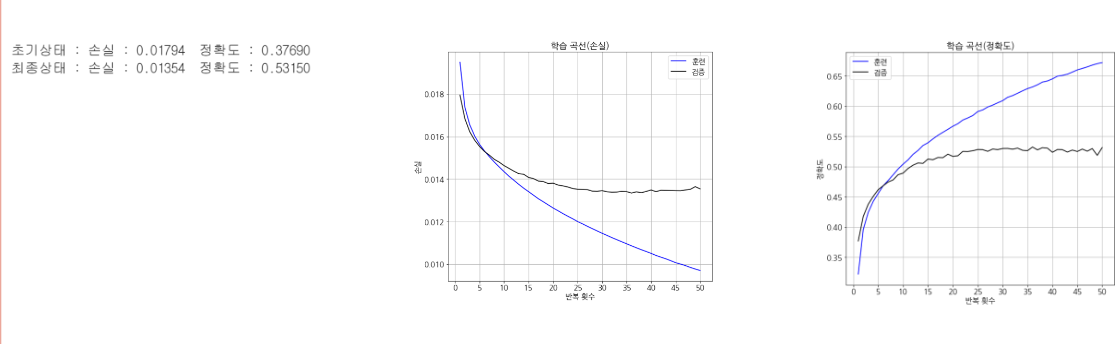
- 해석
- 검증 데이터에 대한 그래프로부터 반복 횟수 30회 부근에서 학습이 정체하고 있음
- 검증 데이터에 대한 정확도는 최대 53% 정도에 그침
9.9 모델 정의 (CNN)
CNN 모델 클래스 정의
class CNN(nn.Module):
def __init__(self, n_output, n_hidden):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 32, 3)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d((2,2))
self.flatten = nn.Flatten()
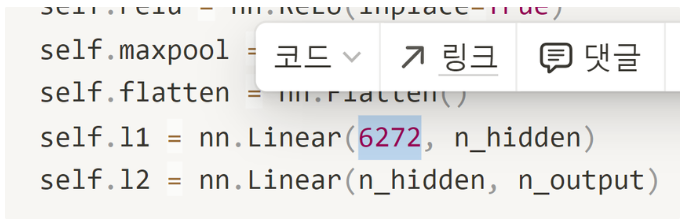
self.l1 = nn.Linear(6272, n_hidden)
self.l2 = nn.Linear(n_hidden, n_output)
self.features = nn.Sequential(
self.conv1,
self.relu,
self.conv2,
self.relu,
self.maxpool)
self.classifier = nn.Sequential(
self.l1,
self.relu,
self.l2)
def forward(self, x):
x1 = self.features(x)
x2 = self.flatten(x1)
x3 = self.classifier(x2)
return x3
- features → flatten → classifier
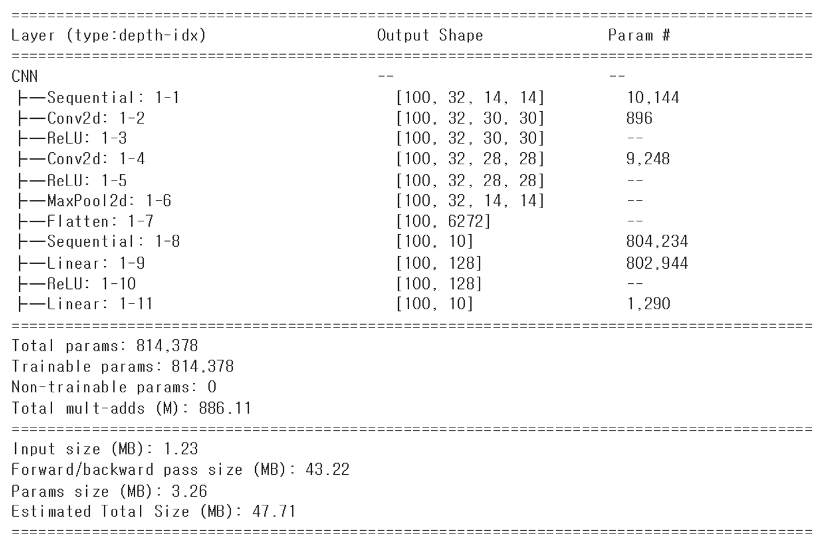
모델 개요 표시
print(net)

summary(net, (100, 3, 32, 32), depth=1)
9.10 결과 (CNN)
모델 초기화와 학습
# 난수 초기화
torch_seed()
# 모델 인스턴스 생성
net = CNN(n_output, n_hidden).to(device)
# 손실 함수: 교차 엔트로피 함수
criterion = nn.CrossEntropyLoss()
# 학습률
lr = 0.01
# 최적화 함수: 경사 하강법
optimizer = optim.SGD(net.parameters(), lr=lr)
# 반복 횟수
num_epochs = 50
# 평가 결과 기록
history2 = np.zeros((0,5))
# 학습
history2 = fit(net, optimizer, criterion, num_epochs, train_loader2, test_loader2, device, history2)

- 전결합형은 데이터의 건수에 맞춰 가중치 행렬이 준비되었지만, CNN은 고정된 길이의 커널 행렬이 준비되어 있으므로, 어떤 크기의 입력이 들어와도 상관없다
- 대신, classifier에서 선형함수가 시작되는 부분의 입력 차원수는 미리 계산해놓아야 함!! (변수로 처리할 수 있지 않나? -> 코드로 구현하여 가능하게 할 수 있음! 아니면, Adaptive 함수를 사용하는 것도 가능!)
여기 6272
평가
evaluate_history(history2)
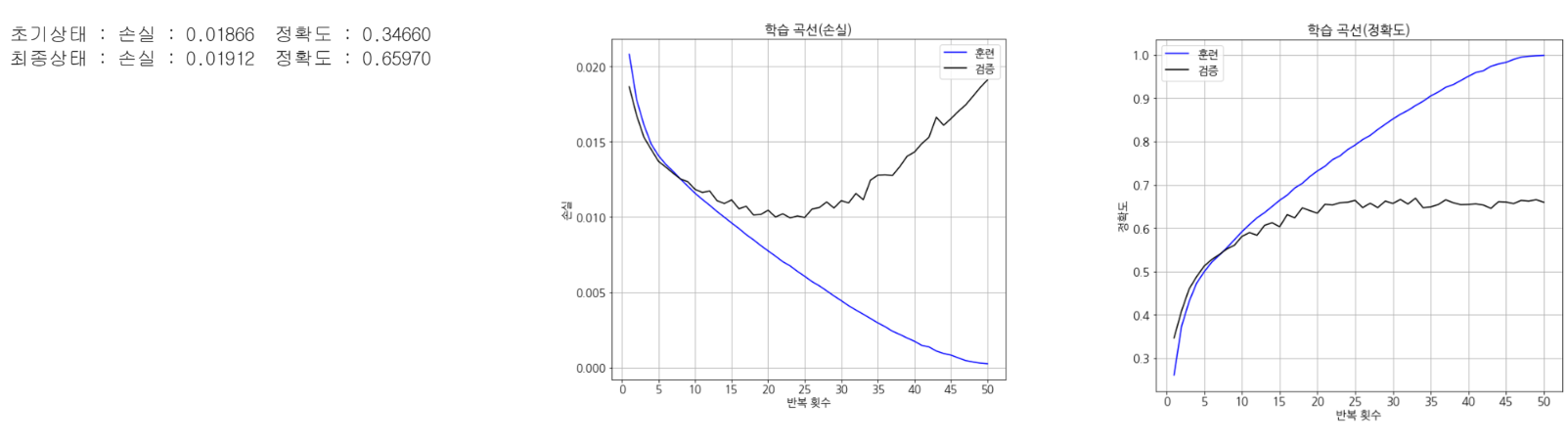
- 정확도가 66%로 향상함! (전결합형은 53%)
show_images_labels(test_loader2, classes, net, device)
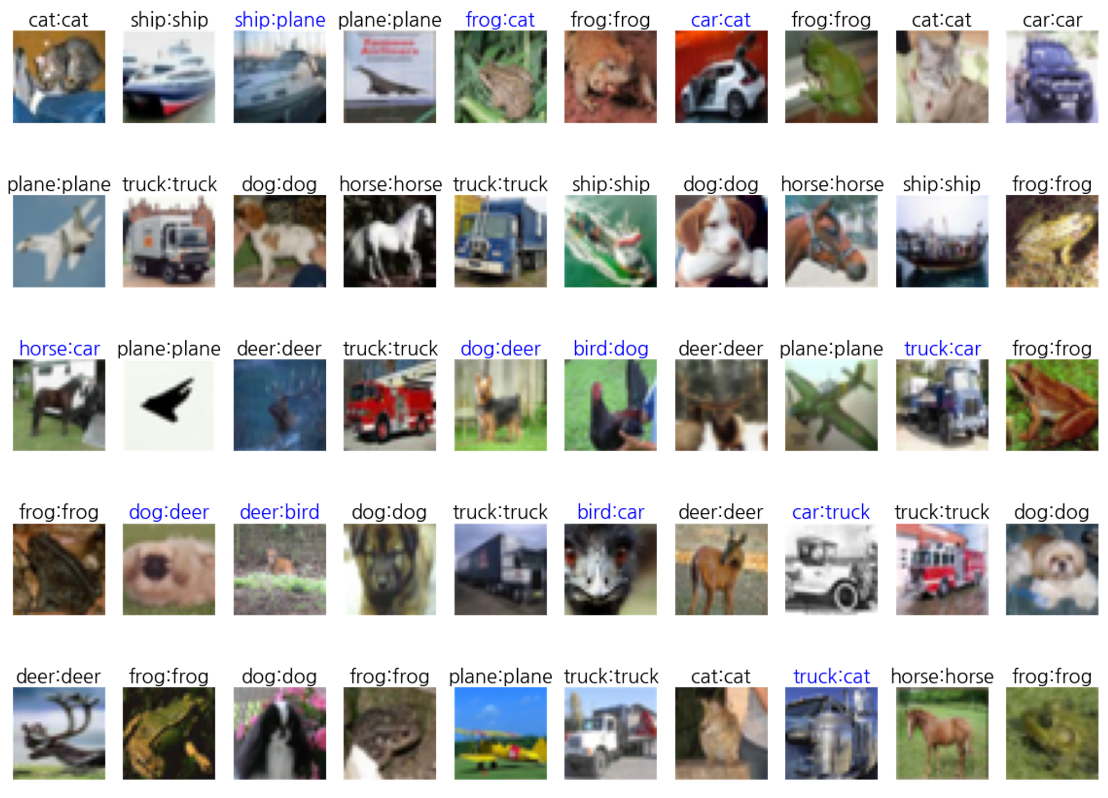
⇒ 그러나, 여전히 정확도가 높지는 않음
⇒ 튜닝이 필요하다 (10장에서 튜닝 기법 내용이 나온다!)
'프로그래밍 책 > 파이토치 딥러닝 프로그래밍' 카테고리의 다른 글
| 11. 사전 학습 모델 이용하기 | 파이토치 딥러닝 프로그래밍 (1) | 2024.05.16 |
|---|---|
| 10. 튜닝 기법 | 파이토치 딥러닝 프로그래밍 (1) | 2024.04.21 |
| 8. MNIST를 활용한 숫자 인식 | 파이토치 딥러닝 프로그래밍 (1) | 2024.04.21 |
| 4. 예측 함수 정의하기 | 파이토치 딥러닝 프로그래밍 (1) | 2024.04.17 |
| 3. 처음 시작하는 머신러닝 | 파이토치 딥러닝 프로그래밍 (0) | 2024.04.17 |
'프로그래밍 책/파이토치 딥러닝 프로그래밍' Related Articles
more



