
열심히 코딩 하숭!
12. 사용자 정의 데이터를 활용한 이미지 분류 | 파이토치 딥러닝 프로그래밍 본문
12 사용자 정의 데이터를 활용한 이미지 분류
12.1 문제 정의하기
개미와 벌 분류 문제
- 훈련 데이터 244개
- 검증 데이터 153개
- JPEG 형식
- 다중 분류로 진행
시베리안 허스키와 늑대 분류 문제
- 훈련 데이터 40건
- 검증 데이터 10건
12.3 데이터 준비
데이터 다운로드, 압축 해제, 트리 구조 출력
- 파이썬 함수 말고 리눅스 커맨드를 사용!
- 다운로드: wget
- 압축 해제: unzip
- 트리 구조 출력: tree
- tree 커맨드의 경우 (구글 코랩에 기반하는 OS에 포함되어 있지 않으므로) 일단 apt 커맨드를 통해 tree 커맨드를 도입한 다음 사용한다
tree 커맨드 install
!pip install torchviz | tail -n 1
!pip install torchviz | tail -n 1 w = !apt install tree
print(w[-2])
다운로드
- wget 커맨드로 zip 파일 다운로드
- 학습 대상의 데이터가 인터넷에서 다운로드 가능한 형태여야 함
# 데이터 다운로드
w = !wget -nc <https://download.pytorch.org/tutorial/hymenoptera_data.zip>
# 결과 확인
print(w[-2])

압축 해제
- unzip 커맨드로 zip파일 압축 해제
# 압축 해제
w = !unzip -o hymenoptera_data.zip
# 결과 확인
print(w[-1])
- -o 옵션을 붙인 이유 → 두 번 이상 실행할 때 파일을 덮어쓰게 하기 위해
# 트리 구조 출력
!tree hymenoptera_data- 결과
hymenoptera_data
├── train
│ ├── ants
│ │ ├── 0013035.jpg
│ │ ├── 1030023514_aad5c608f9.jpg
(생략)
├── 936182217_c4caa5222d.jpg
└── abeja.jpg
6 directories, 398 files
Transforms 정의
# Transforms 정의
# 검증 데이터 : 정규화
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5)
])
# 훈련 데이터 : 정규화에 반전과 RandomErasing 추가
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5),
transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)
])- 검증 데이터
- transforms.Resize(256) → 화면 전체를 우선 256x256 으로 확대 또는 축소
- transforms.CenterCrop(224) → 중앙의 224x224 부분을 떼어냄
- 훈련 데이터
- RandomResizedCrop → 224x224로 반환하는 것은 맞는데, 랜덤 요소를 도입하여 데이터 증강의 효과를 냄
ImageFolder 사용
- 데이터셋 정의를 위해 필요한 변수 정의
# 베이스 디렉터리
data_dir = 'hymenoptera_data'
# 훈련 데이터 디렉터리와 검증 데이터 디렉터리 지정
import os
train_dir = os.path.join(data_dir, 'train')
test_dir = os.path.join(data_dir, 'val')
# join 함수 결과 확인
print(train_dir, test_dir)
# 분류하려는 클래스의 리스트 작성
classes = ['ants', 'bees']

데이터셋 정의
# 데이터셋 정의
# 훈련용
train_data = datasets.ImageFolder(train_dir,
transform=train_transform)
# 훈련 데이터 이미지 출력용
train_data2 = datasets.ImageFolder(train_dir,
transform=test_transform)
# 검증용
test_data = datasets.ImageFolder(test_dir,
transform=test_transform)- 디렉터리명을 지정하여 파이토치에서 데이터를 사용할 수 있도록 한다
- train_data2의 경우, 훈련용 이미지를 직접 볼 수 있도록 하기 위해 test_transform을 지정했다
# 데이터 건수 확인
print(f'훈련 데이터 : {len(train_data)} 건')
print(f'검증 데이터 : {len(test_data)} 건')

# 검증 데이터
# 처음 10개와 마지막 10개 이미지 출력
plt.figure(figsize=(15, 4))
for i in range(10):
ax = plt.subplot(2, 10, i + 1)
image, label = test_data[i]
img = (np.transpose(image.numpy(), (1, 2, 0)) + 1)/2
plt.imshow(img)
ax.set_title(classes[label])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, 10, i + 11)
image, label = test_data[-i-1]
img = (np.transpose(image.numpy(), (1, 2, 0)) + 1)/2
plt.imshow(img)
ax.set_title(classes[label])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

데이터로더
- 데이터 양이 적기 때문에, 배치 사이즈는 10으로!
- train_loader2 / test_loader2 → 샘플 이미지 출력을 위해 정의
- 검증 데이터에 대해서도 일부러 shuffle=True로 설정해서 ‘개미’ ‘벌’ 모두 출력할 수 있도록 함
# 데이터로더 정의
batch_size = 10
# 훈련용
train_loader = DataLoader(train_data,
batch_size=batch_size, shuffle=True)
# 검증용
test_loader = DataLoader(test_data,
batch_size=batch_size, shuffle=False)
# 이미지 출력용
train_loader2 = DataLoader(train_data2,
batch_size=50, shuffle=True)
test_loader2 = DataLoader(test_data,
batch_size=50, shuffle=True)
# 검증 데이터(50건)
torch_seed()
show_images_labels(test_loader2, classes, None, None)

12.4 파인 튜닝의 경우
파인 튜닝 구현 코드
# 파인 튜닝의 경우
# 사전 학습 모델 불러오기
# VGG-19-BN 모델을 학습이 끝난 파라미터와 함께 불러오기
from torchvision import models
net = models.vgg19_bn(pretrained = True)
# 난수 고정
torch_seed()
# 최종 노드의 출력을 2로 변경
in_features = net.classifier[6].in_features
net.classifier[6] = nn.Linear(in_features, **2**)
# AdaptiveAvgPool2d 함수 제거
net.avgpool = nn.Identity()
# GPU 사용
net = net.to(device)
# 학습률
lr = 0.001
# 손실 함수 정의
criterion = nn.CrossEntropyLoss()
# 최적화 함수 정의
optimizer = optim.SGD(net.parameters(),lr=lr,momentum=0.9)
# history 파일도 동시에 초기화
history = np.zeros((0, 5))
- 이전 장과 다른 점은 분류 대상이 10에서 2로 바뀌었다는 것 밖에 없음!
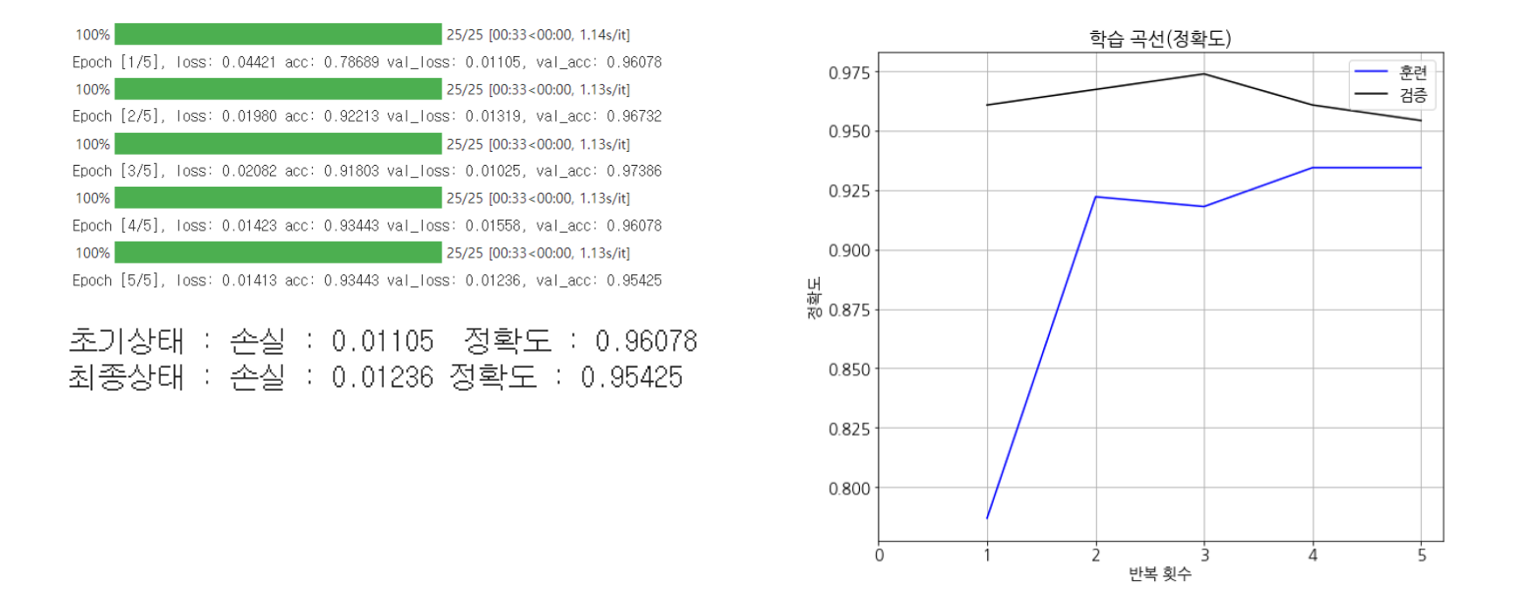
학습
# 학습
num_epochs = 5
history = fit(net, optimizer, criterion, num_epochs,
train_loader, test_loader, device, history)
- 정확도 95.4% 정도 (좋은 결과~)
12.5 전이 학습의 경우
전이 학습 구현 코드
# VGG-19-BN 모델을 학습이 끝난 파라미터와 함께 불러오기
from torchvision import models
net = models.vgg19_bn(pretrained = True)
# 모든 파라미터의 경사 계산을 OFF로 설정
for param in net.parameters():
param.requires_grad = False
# 난수 고정
torch_seed()
# 최종 노드의 출력을 2로 변경
# 이 노드에 대해서만 경사 계산을 수행하게 됨
in_features = net.classifier[6].in_features
net.classifier[6] = nn.Linear(in_features, 2)
# AdaptiveAvgPool2d 함수 제거
net.avgpool = nn.Identity()
# GPU 사용
net = net.to(device)
# 학습률
lr = 0.001
# 손실 함수로 교차 엔트로피 사용
criterion = nn.CrossEntropyLoss()
# 최적화 함수 정의
# 파라미터 수정 대상을 최종 노드로 제한
optimizer = optim.SGD(net.classifier[6].parameters(),lr=lr,momentum=0.9)
# history 파일도 동시에 초기화
history = np.zeros((0, 5))- 파인 튜닝과의 차이점!
- 신경망의 모든 레이어 함수에 대해 경사 계산 X
- 교체된 레이어 함수에 대해서만 경사 계산이 이뤄진다
- 최적화할 파라미터만 작성하여 넘긴다 (여기서는 net.classifier[6])
# 학습
num_epochs = 5
history = fit(net, optimizer, criterion, num_epochs,
train_loader, test_loader, device, history)
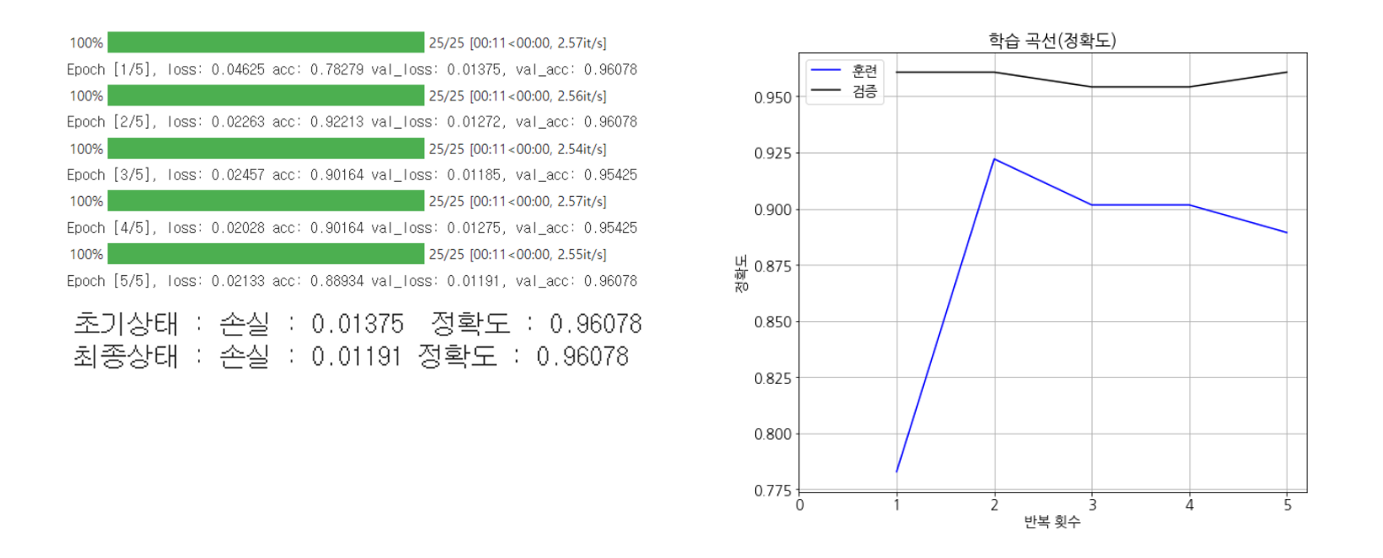
- 여기에서는 파인튜닝과 전이학습의 정확도 차이가 많이 나지 않지만, 일반적으로 학습 데이터의 수가 적을 경우 전이 학습이 훨씬 좋은 정확도를 내는 것으로 알려져있음
12.6 사용자 정의 데이터를 사용하는 경우
직접 수집한 데이터 사용
Transforms 정의
# Transforms 정의
# 검증 데이터 : 정규화
test_transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5)
])
# 훈련 데이터 : 정규화에 반전과 RandomErasing 추가
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5),
transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)
])
- 이번 데이터는 분류 대상을 제외한 부분이 거의 깎여진 상태이므로 처음부터 224 화소로 resize만 실시
데이터셋 정의
# 데이터셋 정의
data_dir = 'dog_wolf'
import os
train_dir = os.path.join(data_dir, 'train')
test_dir = os.path.join(data_dir, 'test')
classes = ['dog', 'wolf']
train_data = datasets.ImageFolder(train_dir,
transform=train_transform)
train_data2 = datasets.ImageFolder(train_dir,
transform=test_transform)
test_data = datasets.ImageFolder(test_dir,
transform=test_transform)
데이터로더
# 데이터로더 정의
batch_size = 5
# 훈련 데이터
train_loader = DataLoader(train_data,
batch_size=batch_size, shuffle=True)
# 훈련 데이터, 이미지 출력용
train_loader2 = DataLoader(train_data2,
batch_size=40, shuffle=False)
# 검증 데이터
test_loader = DataLoader(test_data,
batch_size=batch_size, shuffle=False)
# 검증데이터, 이미지 출력용
test_loader2 = DataLoader(test_data,
batch_size=10, shuffle=True)
- 매우 적은 데이터양을 고려하여 배치사이즈는 5로 설정
모델 학습 코드
# 사전 학습 모델 불러오기
net = models.vgg19_bn(pretrained = True)
for param in net.parameters():
param.requires_grad = False
# 난수 고정
torch_seed()
# 마지막 노드 출력을 2로 변경
in_features = net.classifier[6].in_features
net.classifier[6] = nn.Linear(in_features, 2)
# AdaptiveAvgPool2d 함수 제거
net.avgpool = nn.Identity()
# GPU 사용
net = net.to(device)
# 학습률
lr = 0.001
# 손실 함수 정의
criterion = nn.CrossEntropyLoss()
# 최적화 함수 정의
# 파라미터 수정 대상을 최종 노드로 제한
optimizer = optim.SGD(net.classifier[6].parameters(),lr=lr,momentum=0.9)
# history 파일도 동시에 초기화
history = np.zeros((0, 5))
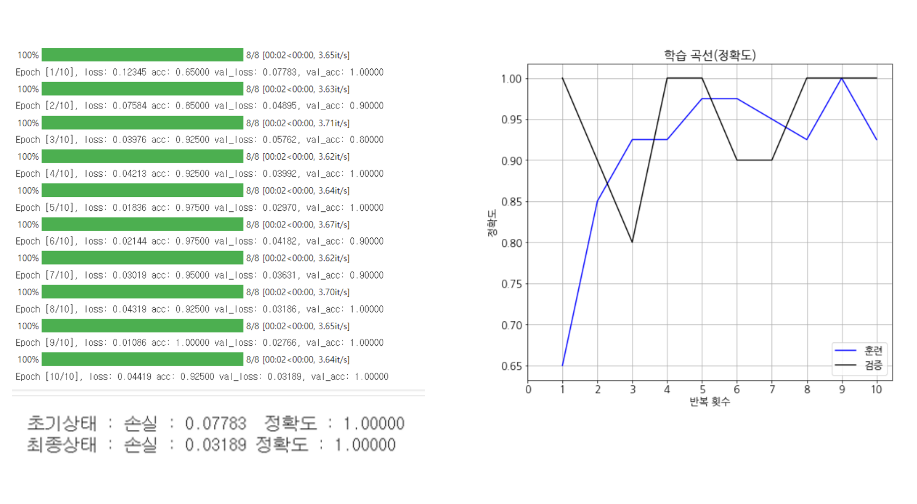
# 학습
num_epochs = 10
history = fit(net, optimizer, criterion, num_epochs,
train_loader, test_loader, device, history)
'프로그래밍 책 > 파이토치 딥러닝 프로그래밍' 카테고리의 다른 글
| 11. 사전 학습 모델 이용하기 | 파이토치 딥러닝 프로그래밍 (1) | 2024.05.16 |
|---|---|
| 10. 튜닝 기법 | 파이토치 딥러닝 프로그래밍 (1) | 2024.04.21 |
| 9. CNN을 활용한 이미지 인식 | 파이토치 딥러닝 프로그래밍 (1) | 2024.04.21 |
| 8. MNIST를 활용한 숫자 인식 | 파이토치 딥러닝 프로그래밍 (1) | 2024.04.21 |
| 4. 예측 함수 정의하기 | 파이토치 딥러닝 프로그래밍 (1) | 2024.04.17 |
'프로그래밍 책/파이토치 딥러닝 프로그래밍' Related Articles
more



