
열심히 코딩 하숭!
pandas 알아보기 | 1주차 - 2 | 파이썬 머신러닝 완벽가이드 본문
* 해당 글은 inflearn의 강의 '[개정판] 파이썬 머신러닝 완벽가이드'를 정리한 글입니다.
회색 - 강의 제목
노란색, 주황색 - 강조
민트색 - 발표할 때 짚고 넘어가면 좋을 것 같은 부분
[이전 글]
글 비밀번호 1234
https://chaesoong2.tistory.com/22
머신러닝 개념, numpy 알아보기 | 1주차 - 1 | 파이썬 머신러닝 완벽가이드
chaesoong2.tistory.com
위 글에 이어 작성합니다.
3일
[0:12:22] 판다스(Pandas) 개요와 기본 API - 01
판다스(Pandas)란?
- 파이썬에서 데이터 처리를 돕는 라이브러리
- 많은 부분이 넘파이 기반으로 작성됨
- CSV 등의 파일을 쉽게 DataFrame으로 변경해 데이터 가공/분석을 편리하게 할 수 있음
DataFrame / Series / Index
- DataFrame : 여러 개의 행과 열로 이루어진 2차원 데이터 구조체 -> shape (3,1)
- Series : 1개의 컬럼 값으로만 구성된 1차원 데이터 구조체 -> shape (3, )
- Index : 고유한 key값 객체 (고유한 id)

Titanic Data 다운로드
- https://www.kaggle.com/competitions/titanic/
import / read_csv()
- read_csv('파일명', '\t') : 이러면 콤마가 아니라 탭으로 구분된 데이터를 사용할 수 있음
import pandas as pd
titanic_df = pd.read_csv('titanic_train.csv')
print('titanic 변수 type:',type(titanic_df))
titanic_df # display() 함수가 생략됨
head() / tail() / display()
- head() : 맨 앞부터 몇 개의 데이터만 추출 (디폴트-5개)
- tail() : 맨 뒤부터 몇 개의 데이터만 추출 (디폴트-5개)
- display() : dataframe의 시각화를 도움 -> 주피터 노트북에서는 생략 가능

제한 조건
- display.max_rows : 최대 행의 개수
- display.max_colwidth : 최대 문자열의 길이
- display.max_columns : 최대 열의 개수
pd.set_option('display.max_rows', 1000) # 최대 행의 개수가 1000개
pd.set_option('display.max_colwidth', 100) # 최대 문자열의 길이가 100
pd.set_option('display.max_columns', 100) # 최대 열의 개수가 100개
titanic_df
shape
- df.shape : dataframe의 행, 열을 나타냄

[0:15:36] 판다스(Pandas) 개요와 기본 API - 02
DataFrame 생성
- 딕셔너리를 Dataframe으로 변환
- 새로운 컬럼명 추가 가능
- 인덱스를 새로운 값으로 할당할 수 있음
#파이썬에 있는 딕셔너리
dic1 = {'Name': ['Chulmin', 'Eunkyung','Jinwoong','Soobeom'],
'Year': [2011, 2016, 2015, 2015],
'Gender': ['Male', 'Female', 'Male', 'Male']
}
# 딕셔너리를 DataFrame으로 변환
data_df = pd.DataFrame(dic1)
print(data_df)
print("#"*30)
# 새로운 컬럼명을 추가
data_df = pd.DataFrame(dic1, columns=["Name", "Year", "Gender", "Age"]) # 일단 Age의 값들은 NaN(Not a Number)로 초기화
print(data_df)
print("#"*30)
# 인덱스를 새로운 값으로 할당.
data_df = pd.DataFrame(dic1, index=['one','two','three','four'])
print(data_df)
print("#"*30)
df.columns / df.index / df.index.value

info()
- Dataframe의 컬럼명, 데이터 타입, Null 건수, 데이터 건수 정보 제공

df.describe()
- 데이터 값들의 평균, 표준편차, 4분위 분포도 제공
- 숫자형 컬럼들에 대해서만 제공

4일
[0:06:03] 판다스 value_counts 메소드 소개
value_counts()
- 동일한 개별 데이터 값이 몇건 있는지 제공

- Series와 Dataframe 모두 사용 가능
- dropna=False : Null 값도 포함하여 계산 (디폴트는 Null 값 계산 X)
print('titanic_df 데이터 건수:', titanic_df.shape[0])
print('기본 설정인 dropna=True로 value_counts()')
# value_counts()는 디폴트로 dropna=True 이므로 value_counts(dropna=True)와 동일.
print(titanic_df['Embarked'].value_counts())
print(titanic_df['Embarked'].value_counts(dropna=False))
- Dataframe에도 value_counts() 적용 가능

[0:12:22] 판다스 DataFrame의 변환, 컬럼 세트 생성/수정
리스트, ndarray, dict -> Dataframe
- pd.DataFrame() 함수 사용
# 3개의 칼럼명이 필요함.
col_name2=['col1', 'col2', 'col3']
# 2행x3열 형태의 리스트와 ndarray 생성 한 뒤 이를 DataFrame으로 변환.
list2 = [[1, 2, 3],
[11, 12, 13]]
array2 = np.array(list2)
print('array2 shape:', array2.shape )
df_list2 = pd.DataFrame(list2, columns=col_name2)
print('2차원 리스트로 만든 DataFrame:\n', df_list2)
df_array2 = pd.DataFrame(array2, columns=col_name2)
print('2차원 ndarray로 만든 DataFrame:\n', df_array2)# Key는 칼럼명으로 매핑, Value는 리스트 형(또는 ndarray)
dict = {'col1':[1, 11], 'col2':[2, 22], 'col3':[3, 33]}
df_dict = pd.DataFrame(dict)
print('딕셔너리로 만든 DataFrame:\n', df_dict)
Dataframe -> 리스트, ndarray, dict
- 중요: ndarray로 변환할 때 df.values 사용
# DataFrame을 ndarray로 변환
array3 = df_dict.values
print('df_dict.values 타입:', type(array3), 'df_dict.values shape:', array3.shape)
print(array3)
# DataFrame을 리스트로 변환
list3 = df_dict.values.tolist()
print('df_dict.values.tolist() 타입:', type(list3))
print(list3)
# DataFrame을 딕셔너리로 변환
dict3 = df_dict.to_dict('list')
print('\n df_dict.to_dict() 타입:', type(dict3))
print(dict3)
DataFrame 칼럼 데이터 생성 / 수정
- 아래와 같은 과정을 통해 손쉽게 가능
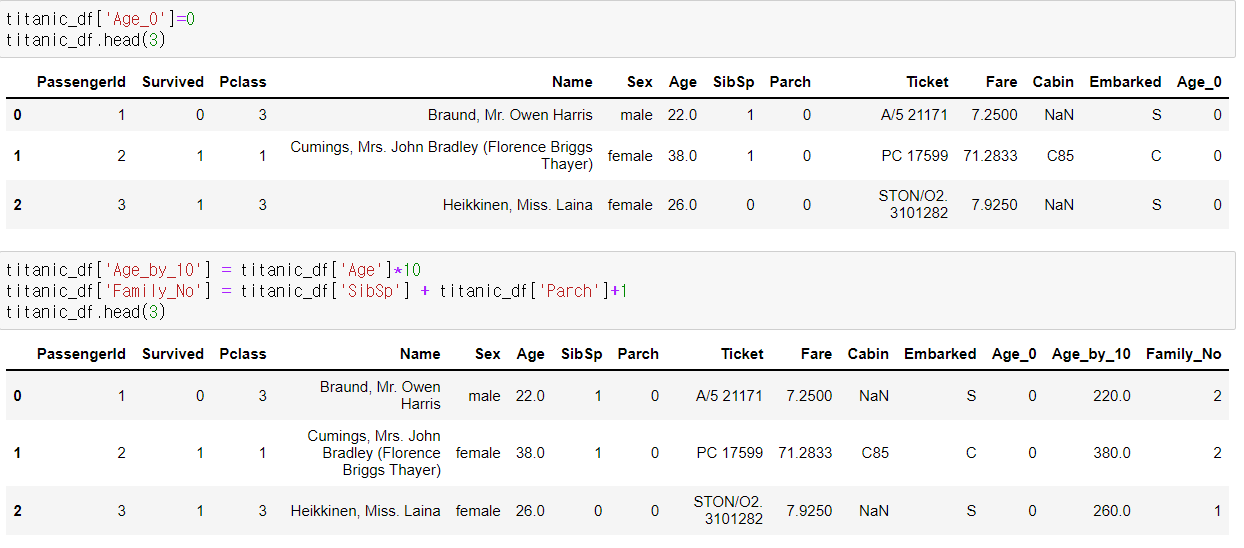

[0:10:57] 판다스 DataFrame의 데이터 삭제하기
axis(축) 삭제
- drop() 함수 사용 : axis = 1
titanic_drop_df = titanic_df.drop('Age_0', axis=1 )- inplace=True일 경우 호출한 DataFrame에 drop의 결과가 반영됨
drop_result = titanic_df.drop(['Age_0', 'Age_by_10', 'Family_No'], axis=1, inplace=True)- axis = 0일 경우, row 방향으로 데이터 삭제
titanic_df.drop([0,1,2], axis=0, inplace=True)
[0:16:25] 판다스 Index객체 이해
Index란?
- Dataframe과 Series의 레코드를 고유하게 식별하는 객체
- 하지만, 판다스 Index는 별도의 컬럼값이 아님! -> 오직 식별용으로만 사용됨
- 고유하기만 하면 index의 값으로 문자형, Datetime 등등 상관없음
- indexes[0] = 5 이런 식으로 개별 값을 변화시킬 수 없음
reset_index()
- 새롭게 인덱스를 연속 숫자형으로 할당
- 기존 인덱스는 'index'라는 새로운 컬럼명으로 추가됨

[0:08:29] 판다스 데이터 인덱싱과 필터링 - 01
[] : 컬럼 기반 필터링
# DataFrame객체에서 []연산자내에 한개의 컬럼만 입력하면 Series 객체를 반환
series = titanic_df['Name']
# DataFrame객체에서 []연산자내에 여러개의 컬럼을 리스트로 입력하면 그 컬럼들로 구성된 DataFrame 반환
filtered_df = titanic_df[['Name', 'Age']]
# DataFrame객체에서 []연산자내에 한개의 컬럼을 리스트로 입력하면 한개의 컬럼으로 구성된 DataFrame 반환
one_col_df = titanic_df[['Name']]
불린 인덱싱
- 조건식에 따른 필터링 제공


[0:15:06] 판다스 데이터 인덱싱과 필터링 - 02
loc[]
- 명칭 기반 인덱싱 -> '컬럼명'
data_df.loc['one', 'Name']
- 현재 dataframe의 index가 문자열이므로 정수형 0은 error를 발생시킴

- 슬라이싱의 경우 모두 반영됨

- 불린 인덱싱 가능
iloc[]
- 위치 기반 인덱싱 -> 'index값'
print("\n iloc[1, 0] 두번째 행의 첫번째 열 값:", data_df.iloc[1,0])
print("\n iloc[2, 1] 세번째 행의 두번째 열 값:", data_df.iloc[2,1])
print("\n iloc[0:2, [0,1]] 첫번째에서 두번째 행의 첫번째, 두번째 열 값:\n", data_df.iloc[0:2, [0,1]])
print("\n iloc[0:2, 0:3] 첫번째에서 두번째 행의 첫번째부터 세번째 열값:\n", data_df.iloc[0:2, 0:3])
print("\n 모든 데이터 [:] \n", data_df.iloc[:])
print("\n 모든 데이터 [:, :] \n", data_df.iloc[:, :])
- 정수형 값만 사용 가능하므로 data_df.iloc['one', 0] <- 이런식으로 사용하면 error가 남
- 보통 Target이 마지막 column인 경우가 많아서, 아래와 같이 많이 쓰임
print("\n 맨 마지막 칼럼 데이터 [:, -1] \n", data_df.iloc[:, -1])
print("\n 맨 마지막 칼럼을 제외한 모든 데이터 [:, :-1] \n", data_df.iloc[:, :-1])
- iloc는 불린 인덱싱을 지원하지 않음
5일
[0:17:30] 판다스 DataFrame의 정렬 그리고 Aggregation함수와 Group by 수행
df.sort_values()
- 해당 컬럼 값으로 정렬
- 오름차순 정렬이 기본 (내림차순은 ascending=False)

Aggregation 함수
- sum(), max(), min(), count(), mean()

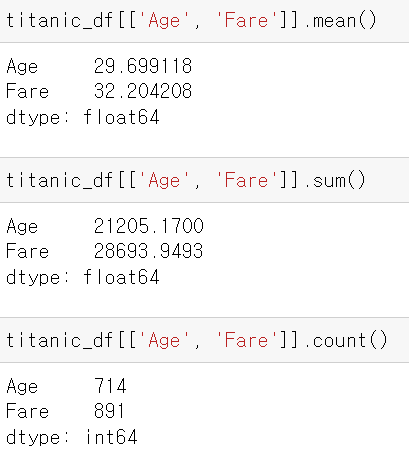
groupby() 함수
- group by 하려는 컬럼명을 입력받으면, DataFrameGroupBy 객체를 반환

- agg 함수를 사용해 다양한 결과값을 같이 출력할 수도 있음


[0:06:56] DataFrame의 Groupby시 Named Aggregation적용
agg 함수 사용 시 유의사항
- dic에 같은 key값을 두개 이상 적게되면, 뒤에 적은 value값만 반영됨

- 아래와 같은 방법으로 해결할 수 있음

[0:05:17] 판다스 결손 데이터 처리하기
df.isna()
- 결손 데이터 여부 확인


fillna()
- 결손 데이터 대체하기
# 문자열로 채우기
titanic_df['Cabin'] = titanic_df['Cabin'].fillna('C000')
# 평균 값으로 채우기
titanic_df['Age'] = titanic_df['Age'].fillna(titanic_df['Age'].mean())
[0:04:28] 판다스 nunique와 replace의 활용
nunique()
- 컬럼이 가지는 고유한 값의 개수를 출력해줌

replace()
- 값을 변경할 수 있음
# Sex의 male값을 Man
replace_test_df['Sex'].replace('male', 'Man')
# 두개 이상의 replace
replace_test_df['Sex'] = replace_test_df['Sex'].replace({'male':'Man', 'female':'Woman'})
# null값을 replace
replace_test_df['Cabin'] = replace_test_df['Cabin'].replace(np.nan, 'C001')
[0:09:27] 판다스 람다식 적용하여 데이터 가공하기
apply() lambda식
- lambda식을 적용하여 함수 사용 효과를 낼 수 있음

- 보통은 이렇게 함수를 선언하여 사용하는 게 편하다
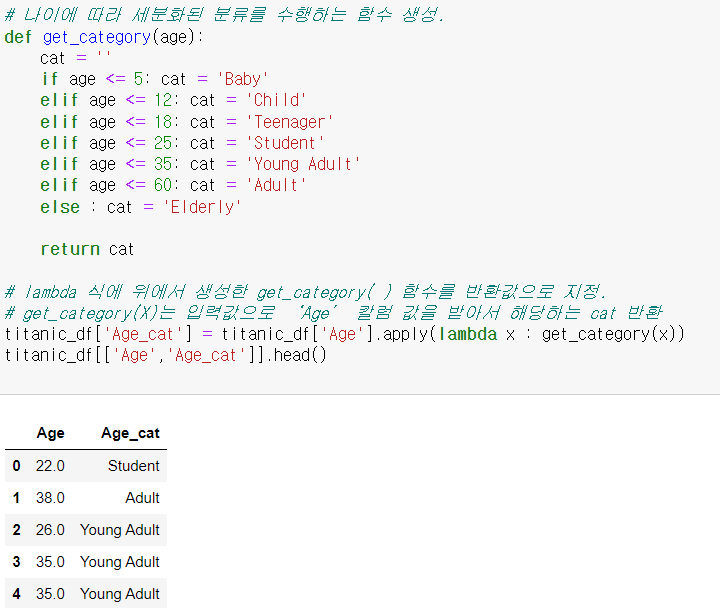
[0:04:04] 파이썬 기반의 머신러닝과 생태계 이해 Summary
1주차 공부 후 느낀점
- 작년에 numpy와 pandas에 대한 기본 개념이 없는 상태로 캐글 문제를 푸느라 고생을 했었는데, 기본을 다시 짚고 넘어가니까 어느 상황에 함수들을 사용해야할지 감이 좀 오는 것 같다.
- 함수 위주로 정리하느라 발표할 내용이 많이 없었던 게 조금 아쉽다.
- 연말이라 좀 급박하게 스터디를 준비했는데, 다음주부터는 꼭 매일.. 정해진 시간에 ... 스터디를 하는 채숭이가 되도록.



